Cohere’s open-weight ASR model hits 5.4% word error rate — low enough to replace speech APIs in production pipelines
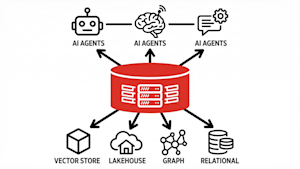
Enterprises building voice-enabled workflows have had limited options for production-grade transcription: closed APIs with data residency risks, or open models that trade accuracy for deployability. Cohere’s new open-weight ASR model, Transcribe, is built to compete on all four key differentiators — contextual accuracy, latency, control and cost. Cohere says that Transcribe outperforms current leaders on …